
{kind=link}
Introduction
Gemini AI, the latest brainchild of the tech titan, is more than just another addition to the AI scene. In a world where technological innovation appears to fly forward with each passing instant, Google has once again positioned itself at the forefront of the artificial intelligence (AI) revolution. It’s a game-changing advancement that will push the limits of machine learning and data processing.
Google’s Gemini AI emerges as a beacon of innovation as we enter the Gemini Era in which the integration of multiple data forms becomes increasingly important. It’s more than just a technological innovation. It’s a view into the future of how we engage with technology, making it a hot issue for tech aficionados, industry professionals, and casual observers alike. In this blog post, we dive deep into the complexities of Gemini AI, investigating its capabilities, versions, and potential implications for the world of technology and beyond. Join me, while I take down the layers of Google’s most ambitious AI project yet.
Table of Contents
What is Gemini AI?
Gemini AI is a multimodal AI model, a sophisticated system capable of analyzing and integrating a wide range of input sources, including text, speech, pictures, and video. This is a significant divergence from usual AI models, which typically deal with multiple mediums separately.
A Multimodal AI Wonder
Gemini AI is, at its heart, Google’s most advanced and competent AI model to date, built to process and understand a wide range of data kinds. Unlike traditional AI models, which often specialize in a single data form, such as text or photos, Gemini AI is built from the ground up to be multimodal. This means it can integrate, analyze, and respond to text, audio, video, photos, and even code in real-time. This multimodality is a breakthrough advance in AI technology, allowing for a more complete and detailed interpretation of complex information.
The Genesis and Vision of Gemini AI
Google’s ambition for Gemini AI is to develop a model that goes beyond typical AI capabilities, providing a more natural, efficient, and complete approach for machines to understand and interact with their surroundings.
Demis Hassabis, the CEO, of Google DeepMind, said to Wired, “Google DeepMind is already looking at how Gemini might be combined with robotics to physically interact with the world”. He also says, “To become truly multimodal, you’d want to include touch and tactile feedback. There’s a lot of promise in applying these sorts of foundation-type models to robotics, and we’re exploring that heavily. We’ve got some interesting innovations we’re working on to bring to future versions of Gemini. You’ll see a lot of rapid advancements next year.”
Inside the Minds of Gemini AI’s Creators: Vision and Insights
Sundar Pichai, CEO, of Google and Alphabet, said, “One of the reasons we got interested in AI from the very beginning is that we always viewed our mission as a timeless mission. It’s to organize the world’s information and make it universally accessible and useful.”
Dennis Hassabis, CEO, of Google DeepMind, said, “I’m super proud and excited to announce the launch of the Gemini era. A first step towards a truly universal AI model. Gemini can understand the world around us in the way that we do and absorb any type of input and output. Gemini was better than any other model out there on these very very important benchmarks. Each of the so different subject areas that we treated it’s as good as the best expert humans in those areas.”
Jeff Dean, Chief Scientist, of Google DeepMind and Google Research, said, “Gemini approach to multimodality is all the kinds of things anyone wants an artificial intelligence system to be able to do and these are capabilities that haven’t existed in computers before.”
Release Date and How to Access Google’s Gemini AI
Gemini is now accessible on Google products in Nano and Pro versions, such as the Pixel 8 phone and the Bard chatbot. Google intends to integrate Gemini into its Search, Ads, Chrome, and other services over time.
Beginning December 13, developers and enterprise clients will be able to access Gemini Pro via the Gemini API in Google’s AI Studio and Google Cloud Vertex AI. Android developers will be able to access Gemini Nano through AICore, which will be available in an early preview.
Different Versions of Google’s Gemini AI
Google said that it has optimized the Gemini 1.0 model for three different sizes –
1. Gemini Ultra
The most powerful and capable model, suitable for exceedingly difficult jobs. It is designed to perform highly complicated activities such as advanced reasoning, coding, and problem-solving. It is efficiently serveable at scale on TPU accelerators due to the Gemini architecture.
Google stated that the Gemini Ultra will be accessible for early experimentation and input to select consumers, developers, partners, and safety and responsibility experts before being made available to developers and enterprise customers at the beginning of 2024.
The company will release “Bard Advanced,” an improved version of Google’s AI-based chatbot that will provide consumers with access to Gemini Ultra’s capabilities.
2. Gemini Pro
A mid-range version that is suitable for a variety of tasks. This version is now powering Google’s English Bard chatbot. The Gemini Pro system employs the Gemini 1.0 model to do a variety of activities such as planning, reasoning, and more.
From December 13, developers and enterprise clients can use the Gemini API in Google AI Studio or Google Cloud Vertex AI to access Gemini Pro. It will be available in English in more than 170 countries.
3. Gemini Nano
The most efficient model, intended for on-device use. According to Google, it may be used offline on Android smartphones and other devices. It contains two Nano versions, with 1.8B (Nano-1) and 3.25B (Nano-2) specifications, aimed at low and high-memory devices, respectively. Gemini is trained by combining smaller Gemini models. It is a 4-bit quantized for deployment and has the best performance in its class.
Google is releasing Gemini Nano on its Pixel 8 Pro smartphone, which was designed to run the on-device AI model. Gemini Nano presently drives features such as Summarise in the Recorder app and is making its way into Smart Reply for Gboard, beginning with WhatsApp.
Starting next year, Gemini Nano power Gboard features will be available on more messaging apps. Google has confirmed that Gemini will be available in more products and services in the next months, including Search, Ads, Chrome, and Duet AI.
Although there was no official statement about the pricing. But Google said to the New York Times, “Clients could pay to google the same price as their current OpenAI rate and get cloud credits, or discounts, thrown in”.
The Architecture of Gemini AI
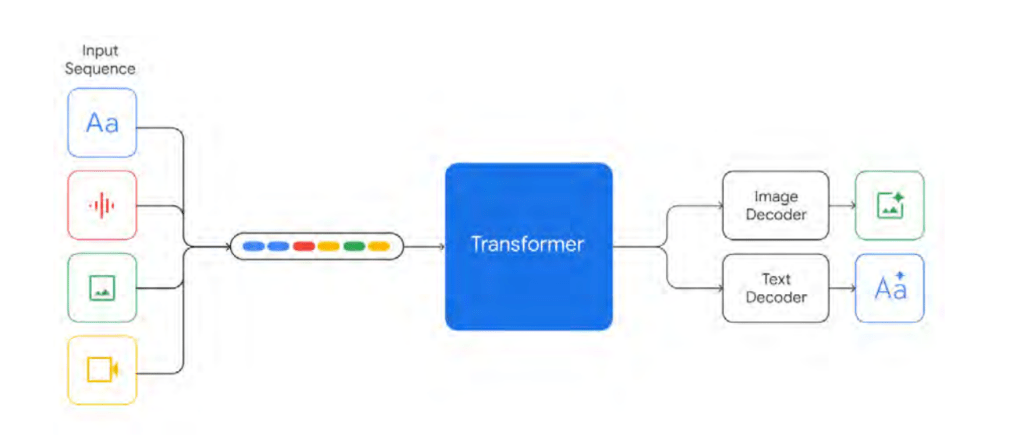
As inputs, Gemini accepts interleaved sequences of text, image, audio, and video (represented by tokens of different colors in the input sequence). It can generate answers that include interleaved graphics and text. Tasks that necessitate a greater understanding. Furthermore, Gemini can directly ingest 16kHz audio inputs from Universal Speech Model (USM) (Zhang et al., 2023) characteristics. This allows the model to capture nuances that are normally lost when audio is mapped to a text input.
Training Infrastructure Of Gemini AI
TPUv5e and TPUv4 were used to train Gemini models, depending on their size and configuration. Gemini Ultra was trained using a vast fleet of TPUv4 accelerators spread across numerous data centers. This is a huge increase in scale over the previous flagship model, PaLM-2, which introduced additional infrastructure issues. As the number of accelerators increases, the mean time between hardware failures in the whole system decreases proportionally. They reduced the frequency of planned reschedules and preemptions. But genuine machine failures are common in all hardware accelerators at such large scales. Due to external factors such as cosmic rays(Assessment of the impact of cosmic-ray-induced neutrons on hardware in the Roadrunner supercomputer, not the ray from outer space).
TPUv4 accelerators are deployed in “SuperPods” of 4096 chips, each connected to a dedicated optical switch, which can dynamically reconfigure 4x4x4 chip cubes into arbitrary 3D torus topologies in around 10 seconds. For Gemini Ultra, they decided to retain a small number of cubes per superpod to allow for hot standbys and rolling maintenance.
Gemini Ultra scale, they combined SuperPods in multiple data centers using Google’s intra-cluster and inter-cluster network. Google’s network latencies and bandwidths are sufficient to support the commonly used synchronous training paradigm. Exploiting model parallelism within superpods and data parallelism across superpods.
Training Dataset of Gemini AI
Gemini models are trained on a dataset that is both multimodal and multilingual. Our pretraining dataset uses data from web documents, books, and code, and includes image, audio, and video data. They applied quality filters to all datasets, using both heuristic rules and model-based classifiers. Also, performed safety filtering to remove harmful content and filtered evaluation sets from the training corpus. The final data mixtures and weights were determined through ablations on smaller models. We stage training to alter the mixture composition during training – increasing the weight of domain-relevant data towards the end of training. We find that data quality is critical to a high-performing model, and believe that many interesting questions remain around finding the optimal dataset distribution for pretraining.
Capabilities of Gemini AI
Traditionally multimodal models are created by stitching together text-only, vision-only, and audio-only models in a suboptimal way at a secondary state. Gemini is multimodal from the ground up so, it can seamlessly have a conversation around modalities and give the best possible response. Which makes it greater than ChatGPT or any other models out there.
General Benchmarks
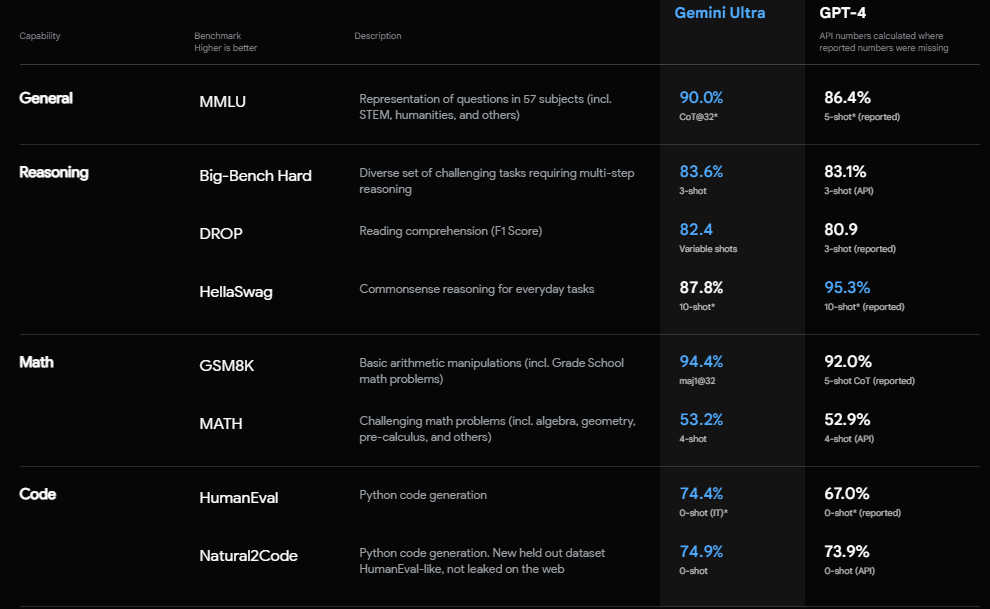
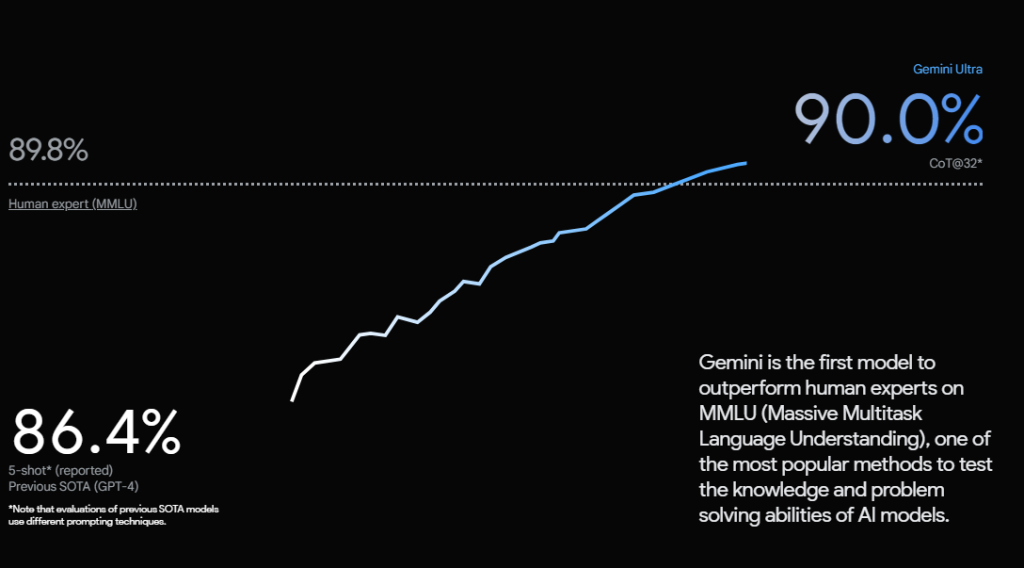
In the image, we see that these are the benchmarks compared with the GPT-4 as it is the next level in the large language model. But currently, GPT-4 has been surpassed by Gemini Ultra in nearly everything.
In General capabilities, MMLU Gemini Ultra got 90% and GPT-4 86.4%.
In Reasoning capabilities on the Big-Bench Hard Gemini Ultra achieved better results than GPT-4. The only Category that didn’t achieve better results was HellaSwag, which is still respectable.
On Math, Gemini Ultra received in GSM8K 94.4%, where GPT-4 92%. And in challenging math problems(which include geometry, algebra, and pre-calculus) Gemini Ultra got 53.2% and GPT-4 52.9%. Also on Code Capabilities, in the HumanEval category Gemini achieved 74.4% and GPT-4 67% and in Natural2Code it got 74.9% and GPT-4 73.9%.
Overall, Gemini Ultra does surpass GPT-4 in these 7 out of 8 categories. Which does make Gemini Ultra the very best large language model to use.
Multimodal Benchmark
On the multimodal benchmark, Gemini AI surpasses GPT-4’s previous capabilities in every category.
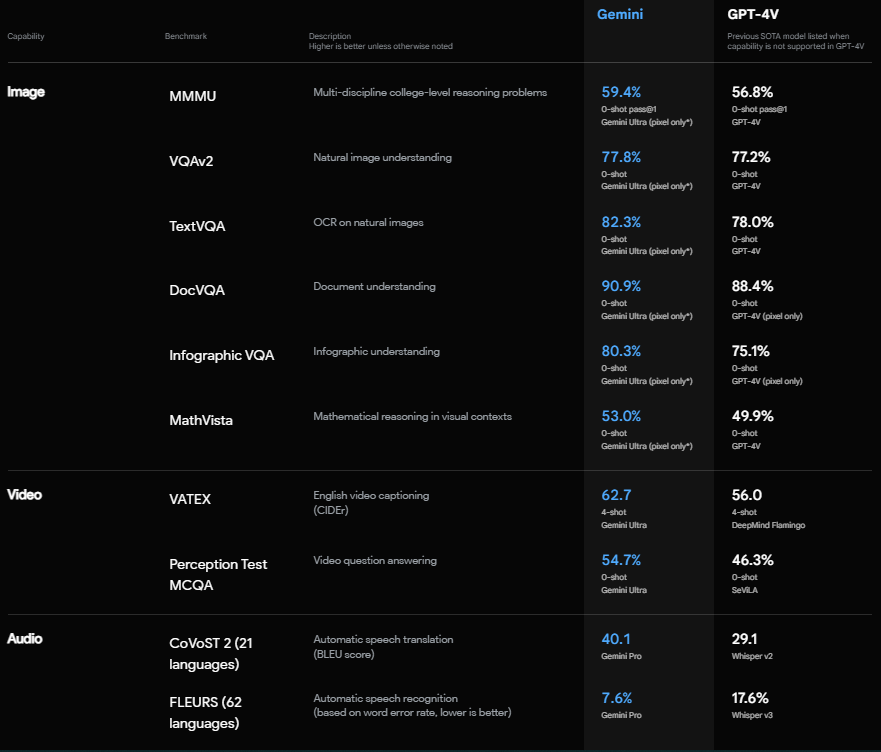
On images
Gemini Ultra outperformed ChatGPT-4 6 out of 6.
On video
ChatGPT 4 doesn’t have video capabilities. So, Gemini was compared with DeepMind Flamingo and SeviLa, which were the best-performing tools in these categories until now. And Gemini Ultra surpassed them by a pretty good margin.
On Audio
Gemini Pro also achieved 40.1% in CoVoST 2(Automatic Translation in a different language). On the other hand, Whisper v2 achieved 29.1%.
Google’s Gemini Ultra’s Reasoning Capabilities
Validating a student’s answer to a physics challenge. The model can accurately recognize and validate all of the handwritten content. In addition to comprehending the text in the image. It must comprehend the issue setup and correctly follow instructions to generate LATEX.

It can be widely used for educational purposes. In the demo, we got to see that Gemini is capable of giving follow-up questions from previous conversions. Which can be useful to practice in studying for students.
Its remarkable capacity to scan, analyze, and grasp data from hundreds of thousands of documents to extract insights. Will help produce breakthroughs at digital speeds in a range of industries, from banking to science.
Google’s Gemini Ultra’s Image Capabilities
Turn images into Code
Gemini AI can turn any image into SVG or HTML/JS code language graphics. Which can be used in graphical animation or even in games.
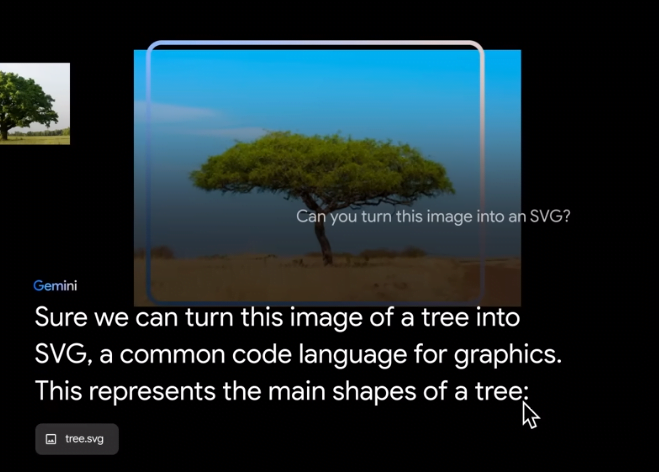
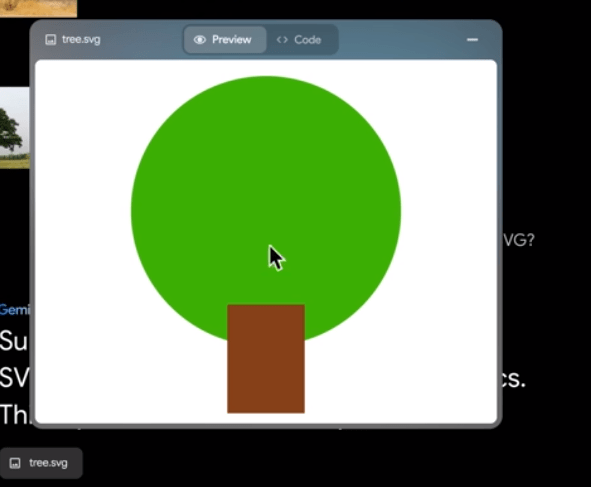
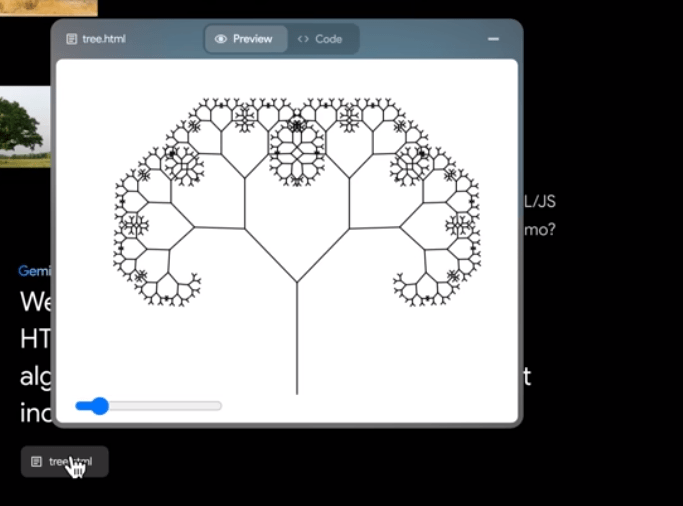
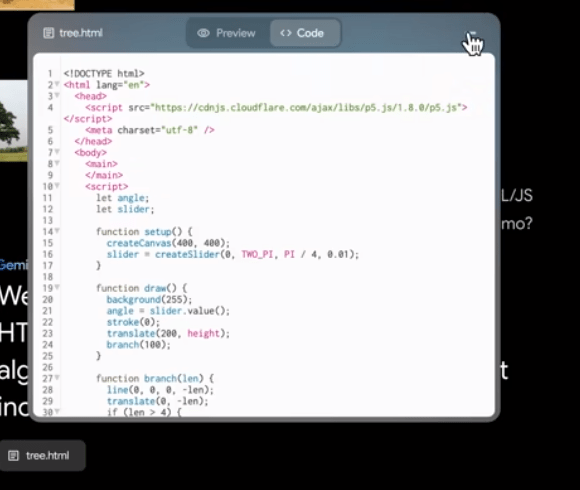
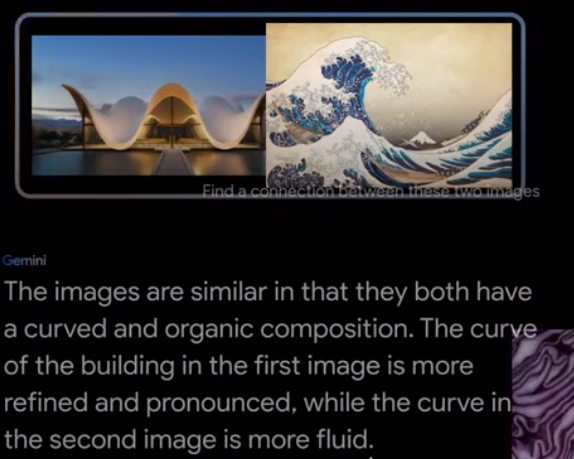
Finding similarities in the images
Gemini AI is capable of finding the similarities of images.


Gemini AI can also Understand Unusual Emojis. It can understand emojis from the emoji kitchen. It can also do a lot of things like understand your surroundings, understanding outfits. You can learn more about them in Google DeepMind.
Security of Gemini AI
Gemini has the most comprehensive safety evaluations of any Google AI model to date, including for bias and toxicity. Google has built dedicated safety classifiers to identify, label, and sort out content involving violence or negative stereotypes, for example. Combined with robust filters, this layered approach is designed to make Gemini safer and more inclusive for everyone. Additionally, it addresses known challenges for models such as factuality, grounding, attribution, and corroboration. They partnered with the industry and broader ecosystem to define best practices and set safety and security benchmarks. Through, organizations like “MLCommons” the “Frontier Model Forum” and its “AI Safety Fund” and “Secure AI Framework (SAIF)“. These were designed to help mitigate security risks specific to AI systems across the public and private sectors.
The Impact of Gemini AI Into Our Life
User Interaction with Technology
The way we engage with technology will be one of the most direct effects of Gemini AI. Its multimodal features, which enable the integration and understanding of many data kinds including text, audio, video, and images, promise to improve the intuitiveness and efficiency of digital interactions. This has the potential to transform user interfaces by making them more responsive and adaptive to specific user needs. Hence, improving the overall user experience.
Advancements in Data Processing and Analysis
The ability of Gemini AI to process and analyze massive amounts of data can lead to substantial advances in sectors. Such as data analytics, research, and scientific discovery. It has the potential to allow for faster and more accurate analysis of big datasets, revealing insights that were previously difficult or impossible to discover. This might hasten innovation in fields as diverse as healthcare, environmental research, and financial services.
Impact on Creative Industries
Gemini AI has the potential to significantly help the creative industries. Its ability to comprehend and generate information could pave the way for new types of art, entertainment, and design. Gemini AI could be used by filmmakers, graphic designers, and artists to explore new kinds of storytelling and visual expression.
Enhancing Educational and Training Programs
By providing more tailored and engaging learning experiences, Gemini AI has the potential to alter educational techniques and training programs. Its ability to digest complex material and deliver explanations has the potential to make learning more accessible and entertaining. Potentially transforming education and professional training across a wide range of professions.
Ethical Considerations and Challenges
With great power comes great responsibility, and the use of Gemini AI is not immune to ethical concerns and obstacles. Concerns about privacy, data security, and the possible exploitation of AI technology must be addressed. Furthermore, frameworks will be required to verify that the use of Gemini AI adheres to ethical principles and benefits to society.
The Competitive Landscape in AI
Gemini AI is a huge step forward in the AI arms race between industry titans. It establishes Google as a powerful opponent to OpenAI and Microsoft. The ability to reshape the competitive environment in AI technology. Gemini AI’s advances may inspire greater research and development in the AI area. Causing other companies to improve their AI products.
Preparing for the Future with Advanced AI
As Gemini AI and other such technology grow more embedded into our daily lives, society will need to adjust. This includes reconsidering job responsibilities and the workforce in light of AI’s capabilities. As well as upgrading educational curricula to educate future generations in a world where advanced AI is prevalent.
Conclusion: Embracing the Dawn of the Gemini Era
As we near the end of our analysis of Google’s Gemini AI, it’s evident that we’re on the verge of a new era in artificial intelligence. One that promises to transform human engagement with technology and its use in a variety of fields. Gemini AI, with its ground-breaking multimodal capabilities, is more than just a technological achievement. It’s a beacon of the unlimited possibilities that AI may provide.
It serves as a stimulus for greater creativity. Its ability to comprehend and handle many sorts of data will spark new ideas, products, and solutions in a variety of industries. From improving customized healthcare to changing artistic and educational industries, Gemini AI lays the groundwork for an exciting future.
Feel free to share your thoughts and insights in the comment below. You can also subscribe to our Newsletter for amazing upcoming news.